
Распознавание текста на устройстве на iOS с помощью SwiftUI
Одна из самых сильных сторон платформы iOS от Apple - это разнообразие встроенных фреймворков. Можно найти множество драгоценных камней, которые обеспечивают простые в использовании, но расширенные функции. Одним из таких примеров является платформа Vision, которая была представлена в iOS 11.
Цель, которую мы хотим достичь в этом руководстве, - реализовать на устройстве приложение для распознавания текста, которое позволяет нашему коду работать даже без подключения к Интернету. Кроме того, мы хотим иметь возможность сканировать документы прямо из нашей камеры и извлекать оттуда текст. Если вы думаете, что для этого потребуется сложный мастер-план машинного обучения темной магии, вы ошибетесь к концу этой статьи.
Вся работа, которую мы будем выполнять, использует встроенные функции, доступные в iOS. Мы также включим SwiftUI в наш небольшой проект, потому что он модный и крутой (если вы еще не пробовали, поверьте мне в этом). Итак, без лишних слов - давайте сразу приступим.
(Примечание: весь код также доступен в этом репозитории на моем Github)
Настройка нашего проекта
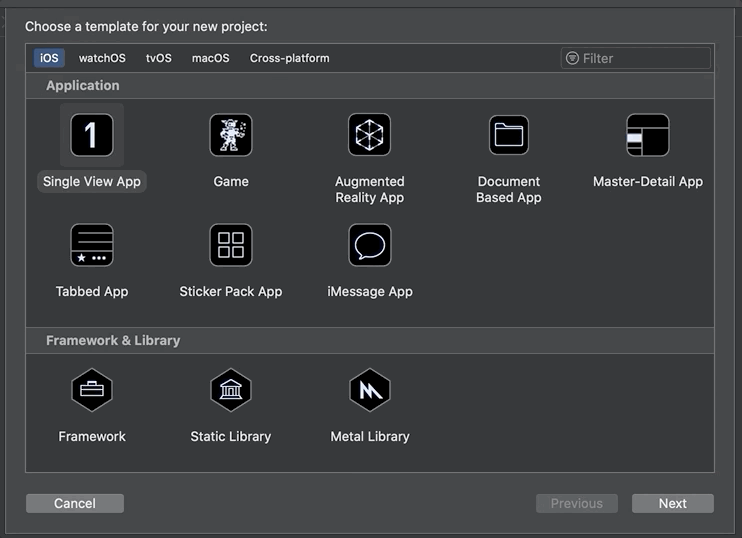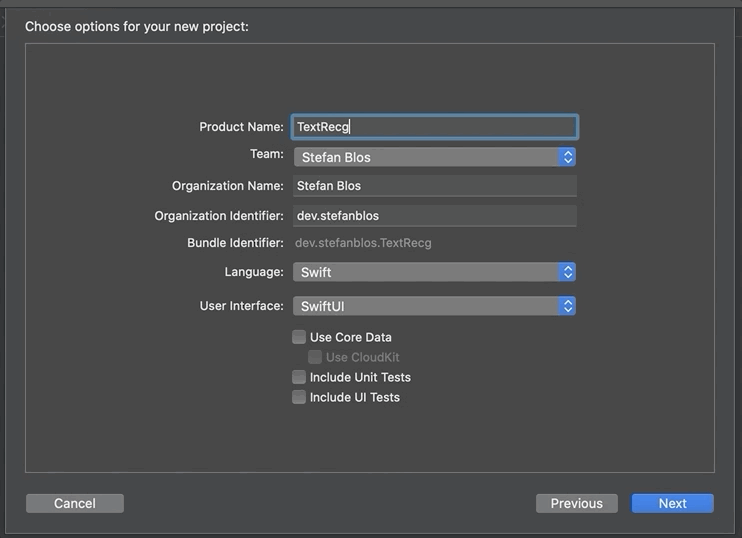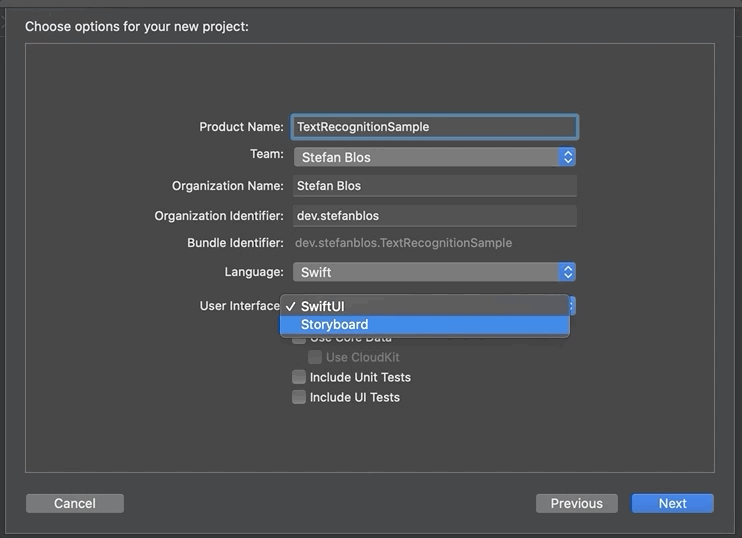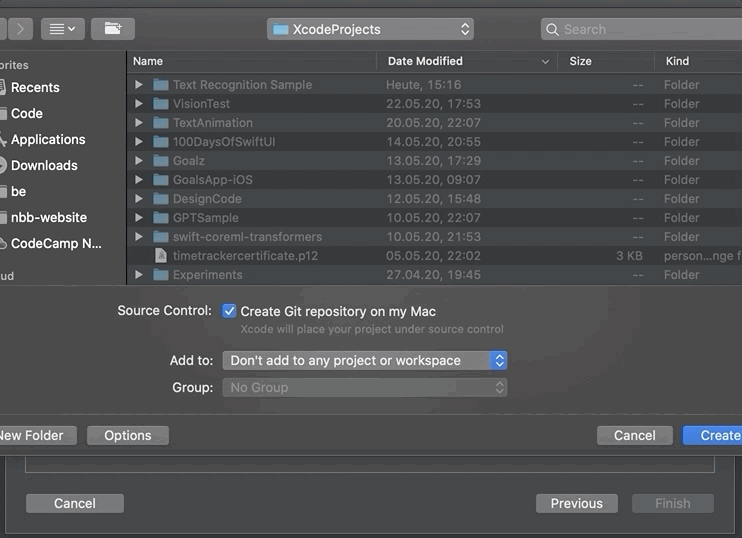
Первое, что нужно сделать, это открыть Xcode и создать новый проект. Мы выбираем Single View App и даем ему красивое, современное, похожее на автозагрузку имя, такое как «Образец распознавания текста». Важно выбрать SwiftUI для пользовательского интерфейса.
Я не буду вдаваться в подробности о структуре проекта здесь, так как предполагаю, что у вас есть базовые знания о SwiftUI. Если нет, то есть множество отличных руководств либо от Apple напрямую, либо в этом списке Пола Хадсона.
Мы собираемся создать базовый интерфейс, ориентированный на функциональность. Это означает, что мы помещаем элемент Text внутрь ScrollView (потому что мы можем сканировать МНОГО текста) и Button, чтобы начать сканирование. Это означает, что наше тело (с небольшой стилизацией) будет:
Здесь следует упомянуть две вещи. Во-первых, мы еще не реализовали функции Button. Вместо этого мы использовали комментарий-заполнитель // start scanning. Во-вторых, элемент Text использует переменную. Чтобы иметь возможность изменять содержимое нашего View, нам нужно создать свойство State, которое мы называем recognizedText:
@State private var recognizedText = "Tap button to start scanning."Идея в том, что мы можем передать это представлению, которое выполняет сканирование. Поскольку это Binding, он позволяет ему манипулировать String. Поэтому мы следим за последовательным потоком данных. Если вы хотите узнать больше о потоках данных в SwiftUI, я очень рекомендую это видео с WWDC 2019. Наш пользовательский интерфейс готов и выглядит так:

Настройте сканирование с помощью VisionKit
Следующим шагом является настройка рабочего процесса распознавания текста. VisionKit - это небольшая платформа, которая позволяет вашему приложению использовать сканер документов системы. Он очень мощный и представляет собой полноценный ViewController с коротким и запоминающимся именем VNDocumentCameraViewController и его дорогой друг VNDocumentCameraViewControllerDelegate (Да, Apple любит длинные имена. В качестве доказательства просто ознакомьтесь с этим замечательным хранилищем).
Как вы могли заметить, в нем есть термин ViewController, который подразумевает, что он происходит от UIKit. Поэтому нам нужно построить небольшой мост, чтобы включить его в наш код SwiftUI. К счастью, с UIViewControllerRepresantable это сделать довольно просто.
Мы создадим новый файл Swift под названием «ScanDocumentView» и заменим импорт Foundation импортом для SwiftUI и VisionKit. Затем мы создаем Struct с именем ScanDocumentView, соответствующий UIViewControllerRepresentable. Чтобы выполнить требования, мы можем использовать небольшую хитрость. Просто добавьте следующую строку:
typealias UIViewControllerType = VNDocumentCameraViewControllerЕсли вы разрешите Xcode добавлять заглушки протокола, он автоматически будет использовать правильные типы и сэкономит вам довольно утомительную работу по вводу текста. После этого мы можем удалить вышеупомянутый typealias и заполнители, чтобы в нашем файле остался следующий код:
У нас все еще есть ошибка, потому что мы еще не реализовали требуемый Coordinator для ответа на события от VNDocumentCameraViewController. Мы исправим это сейчас. Но сначала нам нужно подумать о шагах, которые необходимо предпринять. Чтобы связать методы делегата из ViewController без кода SwiftUI, нам нужно создать Coordinator. Это позволит нам ответить на didFinishWithScan метод делегата VNDocumentCameraViewControllerDelegate и начать со следующего шага нашего конвейера.
Затем мы передаем Binding, который будет автоматически обновлен по завершении обработки. Ему также нужна ссылка на своего родителя. Следовательно, наш Coordinator может быть создан внутри нашей ScanDocumentView структуры и изначально выглядит так:
Нам нужно использовать этот Coordinator в методе makeUIViewController всего с тремя строчками кода:
let documentViewController = VNDocumentCameraViewController()
documentViewController.delegate = context.coordinator
return documentViewControllerПрямо сейчас в нашем Struct есть два недостающих элемента. Во-первых, нам нужно где-то создать нашего координатора. Во-вторых, чтобы извлечь текст, Vision фреймворк должен вступить в игру и творить чудеса.
Мы добавляем makeCoordinator функцию и свойство для нашей recognizedText привязки. Давайте добавим и то, и другое в нашу структуру ScanDocumentView:
@Binding var recognizedText: String
func makeCoordinator() -> Coordinator {
Coordinator(recognizedText: $recognizedText, parent: self)
}Мы добавим магию Vision через секунду, но сначала мы хотим вызвать ViewController сканирования, поскольку он уже полностью функционален и весьма впечатляет в использовании. Итак, вернемся к ContentView и откроем его.
Показывает ScanDocumentView
Есть несколько способов представить ScanDocumentView, но независимо от того, какой из них использовать, мы должны сначала указать причину доступа к камере пользователя. Поэтому мы открываем файл Info.plist, щелкаем правой кнопкой мыши под записями и выбираем Add row. В качестве ключа мы вводим Privacy - Camera Usage Description и добавляем содержательное описание, например «Нам нужно использовать камеру для сканирования документов».

Это создаст запрос для пользователя при первом использовании с просьбой о разрешении. На этом мы, наконец, можем создать остальную часть нашего пользовательского интерфейса. Было бы удивительно видеть, как мало для этого нужно потрудиться.
Мы будем использовать sheet, который будет выдвигаться снизу и отображать пользовательский интерфейс сканирования и скользить обратно вниз, когда мы закончим. Этого легко добиться, но сначала мы добавляем еще одно свойство State, чтобы определить, отображается лист или нет. Добавьте это ниже нашего предыдущего свойства в ContentView:
@State private var showingScanningView = falseЧтобы представить sheet, мы применяем модификатор к самому внешнему VStack. После этого мы можем добавить следующий фрагмент прямо под нашим модификатором navigationBarTitle:
.sheet(isPresented: $showingScanningView) {
ScanDocumentView(recognizedText: self.$recognizedText)
}Последний шаг - заменить комментарий (// start scanning) нашего Button, чтобы установить состояние showingScanningView на true:
self.showingScanningView = trueЗапустите приложение, и вы сможете сканировать документы. Он использует красивый пользовательский интерфейс встроенного в систему сканера документов и позволяет нам уже извлекать данные из вашей камеры. Всего этого можно достичь примерно за 80 строк кода, включая некоторые улучшения пользовательского интерфейса.
Теперь, что касается последней части распознавания текста, мы, наконец, можем добавить платформу Vision, так что давайте сделаем это.
Распознавание текста с Vision
Если мы сейчас отсканируем документ и нажмем кнопку Save, ничего не произойдет. Это имеет смысл, поскольку мы включили только скелет для didFinishWithScan метода делегата в наш Coordinator of ScanDocumentView с пустым телом.
Опять же, нам нужно подумать о том, чего мы хотим достичь. Объект, который мы получаем в результате сканирования, имеет тип VNDocumentCameraScan. Согласно документации, у него будет количество страниц (pageCount) и вспомогательный метод для получения изображения страницы по определенному индексу (imageOfPage(at: Int)). Поэтому мы создадим массив изображений, содержащий все отсканированные документы.
Этот массив можно передать в VNRecognizeTextRequest, который является Vision классом для обработки текста. Для каждой из этих страниц мы извлечем текст, сложим его и, наконец, заменим нашу recognizedText привязку этим текстом.
Затем мы улучшаем наш Coordinator, чтобы можно было извлекать изображения. Добавление вспомогательной функции поможет нам разделить эту логику:
Причина, по которой мы используем здесь CGImage, заключается в том, что это необходимый формат для следующего шага в нашем конвейере.
Далее мы перейдем к основной части этого руководства - распознаванию текста.
Из-за сложности функции распознавания мы разбиваем функцию распознавания на несколько частей:
- Мы создадим переменную с именем
entireRecognizedText, в которой будет храниться захваченный текст. - Мы определяем
VNRecognizeTextRequestс обработчиком завершения иrecognitionLevel, установленным на.accurate(вместо параметра.fast, который можно использовать для приложений реального времени) - Как только он будет обработан, мы извлечем единственного лучшего кандидата из всех наблюдений, данных запросу.
- Добавляем его в переменную
entireRecognizedText - Мы перебираем все изображения и создаем и выполняем
VNImageRequestHandlerс нашим ранее созданным запросом
Итак, начнем:
Мы возвращаем наш распознанный текст, поэтому нам нужно объединить наши две функции внутри метода делегата didFinishWithScan. С помощью всего трех строк кода мы можем извлечь изображения из сканирования, выполнить распознавание текста и установить результат в нашу String переменную привязки, называемую recognizedText.
let extractedImages = extractImages(from: scan)
let processedText = recognizeText(from: extractedImages)
recognizedText.wrappedValue = processedTextЗакрытие нижнего листа
Если мы запустим приложение сейчас, мы все равно ничего не увидим. Нажатие кнопки «Сохранить» по-прежнему не приведет к каким-либо изменениям. Я могу гарантировать вам, что наш код работает - нам нужно только закрыть нижний лист, который мы открыли. Для этого нам нужно использовать переменную @Environment с именем \\.presentationMode.
Это позволяет нам закрыть лист и дать нашему маленькому приложению окончательную функциональность, в которой оно нуждается. Вверху нашей структуры ScanDocumentView нам нужно добавить следующее свойство:
@Environment(\.presentationMode) var presentationModeВ нашем Coordinator под последней строкой нашего didFinishWithScan метода нам нужно вызвать функцию dismiss():
parent.presentationMode.wrappedValue.dismiss()Теперь вы можете запустить приложение на реальном устройстве и увидеть всю магию, которую мы создали.
Резюме
Платформа Vision позволяет нам встраивать мощные функции компьютерного зрения в наши приложения без каких-либо предварительных знаний в предметной области. Вам не нужно быть профессионалом в области компьютерного зрения, чтобы распознавать текст на iOS.
Более того, удивительно, что это работает исключительно на устройстве. Нет необходимости в подключении к Интернету, и он также работает очень быстро. Демонстрационное видео работает на iPhone 8, выпущенном 3,5 года назад. На более современных устройствах это еще быстрее.
Я рекомендую вам попробовать это сами. Вы также можете взглянуть на весь репозиторий на моем Github. Я думаю, что возможности Apple, представленные в рамках Vision, невероятны, и в сочетании со SwiftUI их очень интересно реализовать.
Если вас интересует, как можно использовать машинное обучение на iOS и других платформах, свяжитесь со мной или прокомментируйте эту статью. Вы также можете связаться со мной в Twitter или LinkedIn. Большое спасибо за то, что подписались на эту статью, и большое спасибо Патрику и Филиппу за отличные отзывы.