
В моей предыдущей статье , я представил Core ML, который представляет собой общую структуру машинного обучения. Apple также предоставляет рамки для определенных областей. В этой статье я подробно расскажу о системе Vision для компьютерного зрения. Эта структура основана на Core ML.
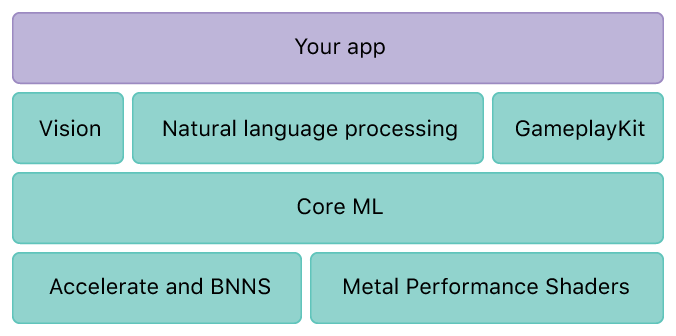
Vision предоставляет нам несколько инструментов для анализа изображения или видео для обнаружения и распознавания лица, обнаружения штрих-кода, обнаружения текста, обнаружения и отслеживания объекта и т. Д. Я объясню каждый инструмент на примере. Пример загружен на GitHub - NilStack / HelloVision.
Проще говоря, в использовании Vision есть три роли. Это запрос, обработчик запросов и наблюдение. Существуют разные типы запросов на анализ изображений для использования разных инструментов в Vision. Например, мы определяем VNDetectFaceRectanglesRequest для обнаружения лица на изображении. В качестве обработчика запросов есть только два типа обработчиков запросов: VNImageRequestHandler и VNSequenceRequestHandler. Один предназначен для одного изображения, а другой - для «последовательности из нескольких изображений». Результаты завернуты в «наблюдения». Информация в наблюдении как ограничивающая рамка результата анализа.
Простой шаблон для использования Vision похож на следующий блок кода.
В каждой функции я показываю только части кода. См. Полный проект на GitHub.
1. Анализ изображений машинного обучения
Это необходимо для анализа изображения с помощью модели Core ML. Соответствующий запрос - VNCoreMLRequest. Я буду использовать новую модель MobileNets от Google. Это для мобильных и встроенных приложений машинного зрения. Вы можете скачать файл модели, преобразованный в формат Core ML компанией Matthijs Hollemans из awesome-CoreML-models.
Вот результат

2. Распознавание лиц
Распознавание лиц помогает находить лица на изображении. Соответствующий запрос - VNDetectFaceRectanglesRequest. Ограничительные рамки для обнаруженных лиц заключаются в результат VNFaceObservations. В этом примере вокруг граней нарисованы прямоугольники.
HandleFaces - это обработчик завершения.
Результат

3. Обнаружение ориентиров на лицах
Обнаружение ориентиров на лицах помогает находить на изображении различные черты лица. Соответствующий запрос - VNDetectFaceLandmarksRequest. Регионы для разных ориентиров помещаются в результаты. В регионе точки будут отмечать ориентиры, такие как глаза, нос, рот и т. Д.
Результат ниже.

4. Обнаружение текста
Обнаружение текста предназначено для обнаружения текстовой области на изображении. Запрос - VNDetectTextRectanglesRequest.
Результат

5. Обнаружение штрих-кодов
Обнаружение штрих-кодов предназначено для обнаружения штрих-кодов на изображении. Но я всегда получаю nil с VNDetectBarcodesRequest и не могу найти документ или образец для справки. Пожалуйста, помогите мне, если вы получите правильный результат с распознаванием штрих-кодов.
6. Отслеживание объектов
Я использую VNImageRequestHandler в предыдущих запросах. Но при отслеживании объектов мне нужно обрабатывать видео, поэтому пора перейти на VNSequenceRequestHandler, который предназначен для «последовательности из нескольких изображений».
Этот пример взят из блога jeffreybergier Начало работы с Vision на iOS 11.
Посмотрим на результат.
Получите полный проект для всех примеров из GitHub - NilStack / HelloVision.
Следующая статья о машинном обучении в iOS 11:
Swift World: что нового в iOS 11 - обработка естественного языка
Наконец, я перечислю официальные ресурсы из официального документа Apple и сессии WWDC.
Рамки видения сессии WWDC 2017: построение на основном машинном обучении
Я буду продолжать обновлять эту статью и пример. Спасибо за ваше время. Нажмите кнопку ❤, чтобы эту статью увидело больше людей. Поговорите с Пэн через Twitter: nilstack | GitHub: nilstack | LinkedIn: Пэн | Электронная почта: [email protected]
Примечание. Swift World - это моя новая публикация, в которой собраны отличные статьи, руководства и коды по Swift. Пожалуйста, подпишитесь, если интересно.