
Логистическая регрессия – это пример контролируемого обучения. В этой статье мы отправим вас в увлекательное путешествие в мир логистической регрессии, где вы узнаете, что это такое, изучите ее основные типы, сравните ее с линейной регрессией, сбалансируете ее преимущества и недостатки и узнаете о ее преимуществах. реальные приложения. Приготовьтесь раскрыть всю мощь логистической регрессии и отправиться в захватывающее путешествие за знаниями, основанными на данных!»
Что такое логистическая регрессия?
Там, где есть непрерывная переменная для прогнозирования, но ее необходимо классифицировать в бинарной форме, мы используем логистическую регрессию. Это контролируемое обучение используется для расчета или прогнозирования бинарной вероятности (да или нет событий).

Например: лихорадка или нет, Рак или нет, приобретение или потеря, Пройдено или Проиграно. Цель логистической регрессии — найти взаимосвязь между независимыми переменными и бинарными зависимыми переменными, принимающими значение 0 или 1.
Графическое представление логистической регрессии:

Линейная регрессия VS логистическая регрессия
И линейная, и логистическая регрессия являются статистическими моделями, но у них есть некоторые ключевые особенности.
Во-первых, давайте посмотрим, что такое линейная регрессия и логистическая регрессия.
Линейная регрессия
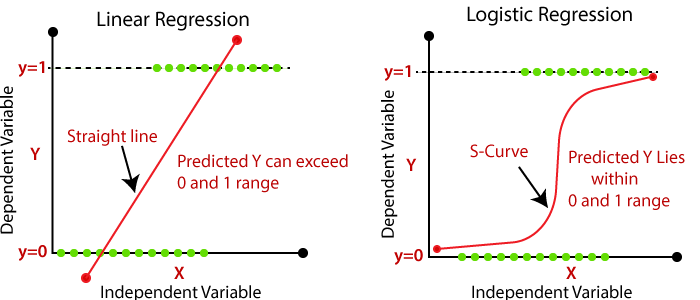
Линейная регрессия используется для моделирования связи между непрерывными зависимыми и независимыми переменными. Выход этой переменной может быть любым значением. По существу, цель этой модели состоит в том, чтобы определить наиболее подходящее линейное уравнение, которое представляет связь между независимой переменной и зависимой переменной.
Математическое выражение для линейной регрессии таково:

где:
- y — зависимая переменная, то есть значение, которое нужно предсказать».
- x - независимая переменная, то есть переменная, которая используется для прогнозирования
- b0 — точка пересечения, а b1 — наклон
- e — остаточная ошибка, означающая зазор между аппроксимируемой линией и точкой. Эта ошибка может быть как положительной, так и отрицательной.
Графическое представление:

Логистическая регрессия
В логистической регрессии вместо подгонки линии мы используем кривую, называемую сигмовидной кривой. На рис. 1.2 S-образная кривая представляет собой сигмовидную кривую, также известную как сигмовидная функция или логистическая функция, которая отображает любое действительное значение в вероятность от 0 до 1.
Функция максимального правдоподобия для оценки параметров является наиболее распространенным методом, используемым в логистической регрессии. Поиск значений коэффициентов, которые максимизируют вероятность наблюдаемых данных, является основной целью этого метода оценки. В процессе обучения модель логистической регрессии изучает коэффициенты для независимых переменных, которые максимизируют вероятность наблюдаемых бинарных результатов в обучающих данных. После того, как модель была обучена с использованием MLE, порог применяется для прогнозирования вероятностей получения бинарной классификации. Поскольку пороговое значение по умолчанию установлено на 0,5, любое значение вероятности выше 0,5 считается положительным, а любое значение ниже 0,5 считается отрицательным. Однако пороговое значение можно регулировать в зависимости от конкретной проблемы.
Математическое представление логистической регрессии таково:

На рис. 1.4 показано, как мы получили логистическую регрессию из линейного уравнения. То есть путем подстановки значения сигмовидной функции через y в уравнение линии.
Основные различия между логистической регрессией и линейной регрессией:
- Линейная регрессия используется для решения проблем регрессии, которые включают прогнозирование непрерывного числового значения в качестве выходных данных, а логистическая регрессия используется для решения проблем классификации, которые включают прогнозирование дискретных категорий или классов как выход.
- Линейный требует наличия связи между зависимой и независимой переменной, и эта связь может быть представлена в виде прямой линии, однако логистика не требует такого рода отношений. Вместо этого он использует вероятность данных по логистической функции (сигмоидальная функция).
- Основываясь на предположении, что все остальные переменные постоянны, коэффициенты линейной регрессии показывают, как изменение предикторов на одну единицу повлияет на результаты. С другой стороны, коэффициенты логистической регрессии, предполагая, что все другие переменные остаются постоянными, показывают изменение логарифмических шансов бинарного результата, связанное с изменением на одну единицу предикторной переменной. (Логарифм шансов — это натуральный логарифм шансов, представляющий собой отношение вероятности того, что бинарный исход произойдет, к вероятности того, что он не произойдет.
- Например: в случае прогнозирования того, сдаст ли студент экзамен или нет, в линейной регрессии (рис. 1.2) мы можем построить линейную линию относительно независимых переменных, таких как час, который студент учился. Однако линейная регрессия может быть не идеальной для этого случая, поскольку она не может точно предсказать, сдаст или не сдаст экзамен студент. Потому что, когда в этом случае применяется линейное уравнение, на выходе будет «пройдено/не пройдено» =,где x — изучаемый час, — коэффициент. Выходное значение не будет находиться в диапазоне от 0 до 1. С другой стороны, в случае логистической регрессии, рис. 1.1, мы можем смоделировать вероятность того, что студент сдаст экзамен или нет, используя сигмовидную функцию. Чтобы максимизировать возможность обнаружения реального выпуска, модель логистической регрессии будет оценивать коэффициенты (0 и 1). Затем, используя пороговое число, ожидаемую вероятность можно использовать для классификации учащегося как сдавшего или не сдавшего экзамен. (например, 0,5).
Типы логистической регрессии
В основном существует три типа логистической регрессии.
· Бинарная логистическая регрессия:
Логистическая регрессия — это отношение между независимыми и зависимыми переменными. Здесь зависимая переменная является двоичной, что означает, что они могут принимать только два возможных значения: 0 или 1. Например, покупает ли человек продукт или нет, сдает ли кто-то экзамен или не сдает экзамен, дождливый день или нет.
·Полиномиальная логистическая регрессия:
Полиномиальная логистическая регрессия — это статистическая модель, используемая для моделирования связи между зависимыми переменными и двумя или более независимыми переменными. Здесь зависимые переменные являются категориальными, их может быть две или более, и они неупорядочены. Например, медицинские заболевания, такие как (болезнь А, болезнь В, болезнь С), животные (собаки, кошки, овцы, мыши).
· Порядковая логистическая регрессия:
Это статистическая модель, используемая для моделирования связи между порядковыми зависимыми переменными и двумя или более независимыми переменными. Здесь зависимая переменная порядковая, то есть упорядоченная, например, оценки учащихся (отлично, хорошо, средне, ниже среднего, плохо) или состояния здоровья (критическое, тяжелое, слабое, здоровое).
Плюсы и минусы логистической регрессии
Преимущества:
· Его можно легко применить, когда данные можно разделить линейно.
· Он обладает прекрасными возможностями распространения на несколько классов, таких как полиномиальная и порядковая логистическая регрессия.
· Он может быстро классифицировать неизвестные записи.
· Хорошо работает со многими простыми наборами данных и имеет хорошую точность, когда набор данных можно разделить линейно.
· Поскольку обновлять логистическую регрессию довольно просто, мы можем в любой момент добавить новые данные в существующий набор данных. Это помогает повысить точность и полезность модели с течением времени.
· Благодаря своим эффективным возможностям обработки он может обрабатывать огромные наборы данных. Это делает его эффективным инструментом для изучения задач бинарной классификации с большими объемами данных.
НЕДОСТАТКИ:
· Основным недостатком логистической регрессии является предположение о линейности между зависимой и независимой переменными. Следовательно, эта регрессия может быть не лучшей моделью для решения задач, в которых взаимосвязь между переменными сложна или логистическая регрессия требует средней мультиколлинеарности или отсутствия мультиколлинеарности между независимыми переменными.
· Существует высокая вероятность того, что модель переоснащена. Чтобы быть точным, в логистической регрессии, когда данные содержат множество независимых переменных, модель может пытаться подогнать шум в данных, что приводит к низкой эффективности обобщения. Точно так же, когда размер выборки слишком мал, данных для оценки может быть недостаточно, а модель может быть переобучена.
· Сложные отношения трудно получить с помощью логистической регрессии.
· Логистическая регрессия требует большого размера выборки, чтобы можно было получить точные оценки коэффициента. Напротив, модель не может точно оценить, когда размер выборки данных минимален.
· Логистическая регрессия ограничена бинарной классификацией и в первую очередь предназначена для решения такого рода проблем классификации, то есть когда значения зависимой переменной могут быть либо 0, либо 1, либо «да», либо "нет". Однако также можно использовать задачи с более чем двумя исходами, такие как полиномиальная классификация.
· Логистическая регрессия чувствительна к планировщикам. Логистическая регрессия может быть чувствительна к выбросам в данных, что может повлиять на оценки коэффициентов и общую производительность модели.
Приложения логистической регрессии.

Существует несколько реальных приложений для логистической регрессии, особенно при попытке прогнозировать бинарные результаты.
1. Область медицины: логистическая регрессия может использоваться для прогнозирования заболевания пациента на основе его истории болезни и других факторов риска. Кроме того, его также можно использовать для выявления факторов риска, изучения результатов терапии и многого другого.
2. Кредитный скоринг. В банках и других финансовых учреждениях модель кредитного рейтинга, основанная на логистической регрессии, чаще всего используется для проверки оценки кредитного риска. Здесь способность заемщика погасить кредит является зависимой переменной, в то время как множество других характеристик, таких как доход заемщика и положение на работе, являются независимыми переменными.
3. Политическое прогнозирование. Логистическую регрессию можно использовать для прогнозирования результатов выборов. Зависимая переменная — победит конкретный кандидат или нет, а независимая переменная — поведение избирателя, политические взгляды. Для прогнозирования результатов выборов компании, проводящие опросы, и средства массовой информации часто используют модели политического прогнозирования, основанные на логистической регрессии.
4. Обнаружение мошенничества. Основная цель этого — выяснить, где произошло мошенническое поведение, на основе входных данных.
5. Игры. Сегментацию игроков и отток игроков можно предсказать с помощью логистической регрессии путем анализа поведения игроков, например частоты игр, типов игр и внутриигровых покупок.
Заключение
В заключение, контролируемое обучение является важным предметом машинного обучения, которое охватывает как модели классификации, так и модели регрессии. Здесь я обсудил логистическую регрессию, которая принадлежит алгоритму классификации. Эта регрессия используется, когда зависимая переменная является категориальной. Несмотря на то, что он имеет различные ограничения, такие как чувствительность к планировщикам и высокая вероятность переобучения, он широко используется в реальных задачах, таких как медицина, кредитный скоринг, политическое прогнозирование и мошенничество.
Чтобы понять практическую сторону логистической регрессии, нажмите ссылку здесь!
Надеюсь, вам понравилось!