
Если вы здесь, то знаете, что PyTorch — одна из самых популярных библиотек среди практиков глубокого обучения. Он очень эффективен, а его гибкость позволяет легко писать собственный код, когда в алгоритмах отсутствуют определенные функции, необходимые в ваших проектах.
Однако работа с кодовой базой PyTorch может быть пугающей, особенно если вы привыкли работать исключительно с высокоуровневыми абстракциями. В этом сообщении блога мы углубимся во внутреннюю архитектуру PyTorch. В частности, мы рассмотрим два важнейших компонента, способствующих эффективным вычислениям: Tensor Wrappers и Kernels.
Мы рассмотрим:
- Tensor Wrapper (например, пакетные тензоры)
- Анатомия вызова оператора
- Написание ядер
- О более эффективном рабочем процессе разработки
- Дополнительные ресурсы
Начнем 🚀
Tensor Wrapper (например, пакетные тензоры)
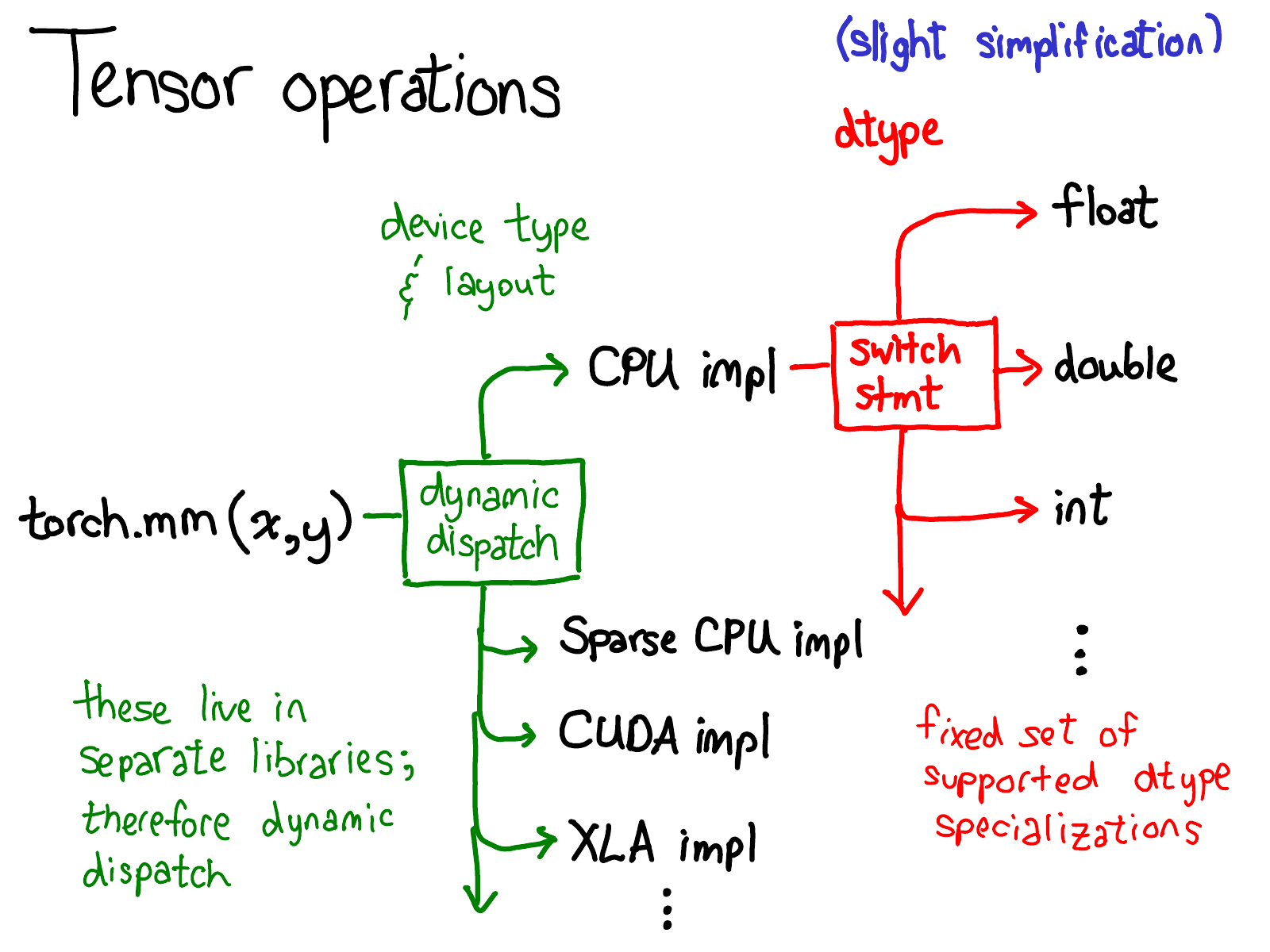
PyTorch Tensor имеет хорошо продуманные метаданные, которые отделяют логическую структуру памяти от физической памяти и предоставляют примитивы для динамической диспетчеризации операторов из интерфейса Python в высокопроизводительный сервер C++. Каждый тензор состоит из метаданных device, layout и dtype.
deviceпозволяет диспетчеризировать операции для каждого устройства (выполняться в ядрах) для повышения эффективности.layoutпозволяет совместно использовать одно и то же выделение памяти на аппаратном уровне для нескольких представлений, отделяя логический тензорный макет от физического макета памяти. Когда требуется доступ к фактической физической памяти,TensorAccessorбудет использовать макет (например, шаг) для доступа к элементам тензора. Вы можете узнать больше оTensorAccessorиз этого блога или этого потрясающего подкаста о внутреннем устройстве PyTorch.dtypeпозволяет диспетчеризировать операции для каждого типа dtype (выполняемые в ядре) для повышения эффективности с помощью макросаAT_DISPATCH_ALL_TYPESв ядрахaten.

Анатомия вызова оператора
При разработке пользовательского оператора с PyTorch необходимо выполнить несколько шагов, прежде чем произойдет какое-либо вычисление. Этот процесс включает разбор аргументов Python, переключение типов переменных, переключение типов данных и, в конечном итоге, диспетчеризацию ядра.
📧 Примечание. Код для отправки отправки генерируется автоматически из aten/src/ATen/native/native_functions.yaml.
Шаг 1. Анализ аргументов Python
- Вы все еще в стране питонов 🥳
- Целью этого шага является передача аргумента Python в привязки C++ через
torch/csrc - Например:
torch.add→THPVariable_add(вtorch._C.VariableFunctions, создается автоматически)
Шаг 2. Переключение типа переменной
- Теперь вы находитесь в серьезной стране
atenC++ 🥸 - Цель этого шага — перенаправить операции на функции, соответствующие
deviceтензора. - Например:
THPVariable_add→VariableDefault::add(вaten/src/Aten/TypeDefault.app, создается автоматически)
Шаг 3. Переключение типа данных
- Теперь вы находитесь в земле ядра 🚀. Здесь все зависит от устройства!
- Цель этого шага — перенаправить операции на функции, соответствующие
dtypeтензора. - К этому шагу мы достигли собственно ядра, оно может быть в лучшей части города (
nativeв C++) или в худшей части города (THв C).
— `VariableDefault::add` → `at::native::add` (в `aten/src/Aten/native/BinaryOps.cpp`)
Стоит еще раз подчеркнуть, что весь код, пока мы не добрались до ядра, генерируется автоматически. Это немного запутанно и запутанно, поэтому, как только у вас будет базовая ориентация в том, что происходит, рекомендуется просто перейти прямо к ядрам.

Написание ядер
При написании ядра необходимо выполнить несколько шагов. Вот краткий обзор:

- Начните с проверки ошибок (например, убедитесь, что входные тензоры имеют правильные размеры).
- Затем нам обычно нужно выделить тензор результата, в который мы собираемся записать вывод, используя
result.resize_(self.sizes());The_вresize_означает модификацию на месте.
3. [Этот шаг не требуется для некоторых устройств] На этом этапе вы должны выполнить второй, dtype диспетчеризацию, чтобы перейти к ядру, которое специализировано для dtype, с которым оно работает. Вы будете использовать макрос AT_DISPATCH_ALL_TYPES, как мы говорили в «Анатомии вызова оператора»
4. Большинству высокопроизводительных ядер нужна своего рода распараллеливание. Реализация зависит от устройства.
5. Наконец, вам нужно получить доступ к данным и выполнить вычисления, которые вы хотели сделать!
- Если вы просто хотите получить значение в каком-то определенном месте, вы должны использовать
TensorAccessor. - Если вы пишете какой-то оператор с очень регулярным доступом к элементам, используйте
TensorIterator. Подробнее оTensorIteratorможно узнать здесь. - Для истинной скорости на ЦП используйте помощники, такие как
binary_kernel_vec.
О более эффективном рабочем процессе разработки
При написании кода нет ничего более неприятного, чем изменение заголовочного файла и ожидание нескольких часов, пока не произойдут необходимые сборки. Вот несколько советов, как максимально повысить эффективность и скорость разработки кода PyTorch:
- Не редактируйте заголовок. Если вы редактируете заголовок, особенно тот, который включен во многие исходные файлы (и особенно если он включен в файлы CUDA), ожидайте очень долгой перестройки. Старайтесь придерживаться редактирования файлов cpp и экономно редактируйте заголовки!
- Не тестируйте с помощью CI: CI — это очень хорошо, но подождите час или два, прежде чем вы получите ответный сигнал. Если вы работаете над изменением, которое потребует большого количества экспериментов, потратьте время на настройку локальной среды разработки.
- Настройте кеш. Если вы работаете с языком C++, настройка CCache может сэкономить вам много времени на сборку. В РУКОВОДСТВЕ ДЛЯ СОТРУДНИКОВ объясняется, как настроить ccache.
Заключение
В заключение отметим, что внутренняя архитектура PyTorch сложна, но очень эффективна. Понимание Tensor Wrappers и Kernels позволяет вам оптимизировать эффективность вычислений, гарантируя, что вы сможете написать собственный код в соответствии с потребностями вашего проекта. Мы надеемся, что этот обзор внутреннего устройства PyTorch поможет вам глубже погрузиться в разработку PyTorch. PyTorch продолжает развиваться и развиваться, поэтому следите за обновлениями с помощью дополнительных ресурсов и руководств по разработке.
Дополнительные ресурсы:
- Официальная вики PyTorch: как создать ядро
- Внутреннее устройство тензорного итератора PyTorch
- Подкаст: TensorIterator
- Как понять исходный код Pytorch?
- Экскурсия по внутреннему устройству PyTorch: Часть 1
- Экскурсия по внутреннему устройству PyTorch: Часть 2
- PyTorch — тур по внутренней архитектуре]
- Подкаст: Подкаст разработчиков PyTorch
- ПиТорч Вики
- Внутреннее устройство PyTorch от автора