
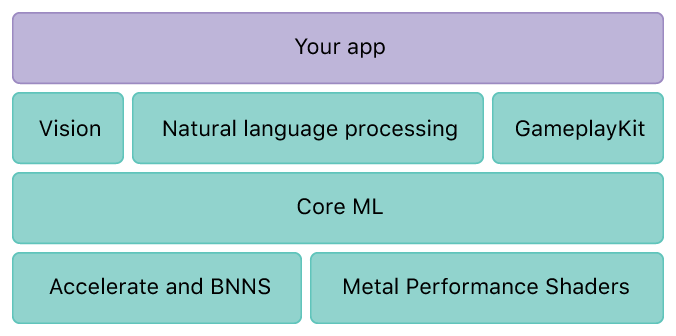
В моята предишна статия представих Core ML, който е обща рамка за машинно обучение. Apple също предоставя рамки за специфични области. В тази статия ще се потопя във Vision framework за компютърно зрение. Тази рамка е базирана на Core ML.
Vision ни предоставя няколко инструмента за анализиране на изображение или видео, за откриване и разпознаване на лице, откриване на баркод, откриване на текст, откриване и проследяване на обект и т.н. Ще обясня всеки инструмент с пример. Примерът е качен в GitHub — NilStack/HelloVision.
Най-просто казано, има три роли в използването на Vision. Те са заявка, заявка за обработка и наблюдение. Има различни типове заявки за анализ на изображения за използване на различни инструменти във Vision. Например ние дефинираме VNDetectFaceRectanglesRequest за откриване на лице в изображение. Като манипулатор на заявки има само два вида манипулатори на заявки: VNImageRequestHandler и VNSequenceRequestHandler. Единият е за едно изображение, а другият е за „поредица от множество изображения“. Резултатите са опаковани в „наблюдения“. Информацията в наблюдението е като ограничителна кутия на резултата от анализа.
Прост шаблон за използване на Vision е като следния кодов блок.
Във всяка функция показвам само части от кодове. Моля, вижте пълния проект в GitHub.
1. Анализ на изображения с машинно обучение
Това е за анализиране на изображение с Core ML модел. Съответната заявка е VNCoreMLRequest. Ще използвам нов модел MobileNets на Google. Той е „за мобилни и вградени визуални приложения“. Можете да изтеглите файла с модела, който е конвертиран във формат Core ML от Matthijs Hollemans от awesome-CoreML-models.
Ето и резултата

2. Разпознаване на лица
Разпознаването на лица е да помогне за намиране на лица в изображение. Съответната заявка е VNDetectFaceRectanglesRequest. Ограничаващите полета за открити лица са обвити в резултата VNFaceObservations. В примера около лицата са начертани правоъгълници.
HandFaces е манипулаторът за завършване.
Резултатът е

3. Разпознаване на забележителности на лицето
Функцията за откриване на забележителности на лицето помага да се намерят различни черти на лицето в изображението. Съответната заявка е VNDetectFaceLandmarksRequest. Регионите за различни забележителности са обвити в резултатите. В даден регион точките ще маркират ориентирите като очи, нос, уста и др.
Резултатът е по-долу.

4. Откриване на текст
Откриването на текст е за откриване на текстова област в изображението. Заявката е VNDetectTextRectanglesRequest.
Резултатът е

5. Откриване на баркодове
Откриването на баркодове е за откриване на баркодове в изображението. Но винаги получавам нула с VNDetectBarcodesRequest и не мога да намеря документ или образец като справка. Моля, помогнете ми, ако получите правилен резултат с откриването на баркодове.
6. Проследяване на обекти
Използвам VNImageRequestHandler в предишни заявки. Но при проследяването на обекти трябва да обработвам видео, така че е време да сменя на VNSequenceRequestHandler, което е за „поредица от множество изображения“.
Този пример е от блога на jeffreybergier Getting Started with Vision on iOS 11.
Да видим резултата.
Вземете пълен проект за всички примери от GitHub — NilStack/HelloVision.
Следващата статия за машинното обучение в iOS 11 е
Swift World: Какво е новото в iOS 11 — Обработка на естествен език
Най-накрая ще изброя официални ресурси от официалния документ на Apple и сесията на WWDC.
„Документ за визия“
WWDC 2017 Session Vision Framework: Надграждане на Core ML
Ще продължа да актуализирам тази статия и пример. Благодаря за отделеното време. Моля, щракнете върху бутона ❤, за да бъде видяна тази статия от повече хора. Говорете с Peng чрез Twitter: nilstack | GitHub: nilstack | LinkedIn: Peng | Имейл: [email protected]
Забележка: Swift World е нова публикация от мен за събиране на отлични статии, уроци и кодове за Swift. Моля, следвайте го, ако се интересувате.