Графика ML с непълни данни
Feature Propagation е просто и изненадващо ефективно решение за обучение върху графики с липсващи характеристики на възли
Повечето графични невронни мрежи обикновено работят при предположението за пълен набор от функции, налични за всички възли. В сценарии от реалния свят функциите често са само частично налични (например в социалните мрежи възрастта и полът могат да бъдат известни само за малка част от потребителите). Показваме, че разпространението на функции е ефективен и мащабируем подход за обработка на липсващи функции в приложения за машинно обучение на графики, който работи изненадващо добре въпреки своята простота.

Тази публикация е в съавторство с Emanuele Rossi.
Моделите на графична невронна мрежа (GNN) обикновено приемат пълен вектор на характеристиките за всеки възел. Да вземем за пример двуслоен GCN модел [1], който има следната форма:
Z = A σ(AXW₁) W₂
Двата входа към този модел са (нормализираната) матрица на съседство Aкодираща структурата на графиката и матрицата на характеристиките X, съдържаща като редове векторите на характеристиките на възлите и извежда вградените възли З. Всеки слой на GCN извършва трансформация на характеристики по възел (параметризирана от обучаемите матрици W₁ и W₂) и след това разпространява трансформираните вектори на характеристики към съседните възли. Важно е, че GCN приема, че всички записи в X са спазени.
В сценарии от реалния свят често виждаме ситуации, при които някои функции на възел може да липсват. Например демографска информация като възраст, пол и т.н. може да бъде достъпна само за малка част от потребителите на социалните мрежи, докато характеристиките на съдържанието обикновено присъстват само за най-активните потребители. В мрежа за съвместно закупуване не всички продукти може да имат пълно описание, свързано с тях. Тази ситуация стана още по-остра, тъй като с нарастващата осведоменост относно дигиталната поверителност данните все повече са достъпни само след изричното съгласие на потребителя.
Във всички горепосочени случаи матрицата на характеристиките има липсващи стойности и повечето съществуващи GNN модели не могат да бъдат директно приложени. Няколко скорошни разработки извличат GNNs модели, способни да се справят с липсващи функции (напр. [2–3]), които обаче страдат в режими на високи нива на липсващи характеристики (›90%) и не се мащабират до графики с повече от няколко милиона ръба .
В нова статия [4], написана в съавторство с Мария Горинова, Бен Чембърлейн (Twitter), Хенри Кенли и Сяоуен Донг (Оксфорд), ние предлагаме функцията за разпространение (FP) [4] като просто, но ефикасно и изненадващо ефективно решение за този проблем. Накратко, FP възстановява липсващите характеристики чрез разпространение на известните характеристики върху графиката. След това реконструираните характеристики могат да бъдат въведени във всяка GNN за решаване на задача надолу по веригата, като класификация на възли или прогнозиране на връзка.

Стъпката на разпространение е много проста: първо неизвестните характеристики се инициализират с произволни стойности [5]. Характеристиките се разпространяват чрез прилагане на (нормализираната) матрица на съседство, последвано от нулиране на известните характеристики до тяхната основна истинска стойност. Повтаряме тези две операции до сближаване на характеристичните вектори [6].

FP може да се извлече от предположението за хомофилия на данните („гладкост“), т.е. че съседите са склонни да имат подобни вектори на характеристиките. Нивото на хомофилия може да се определи количествено с помощта на енергията на Дирихле, квадратна форма, измерваща квадратната разлика между характеристиката на възел и средната стойност на неговите съседи. Градиентният поток на енергията на Дирихле [7] е графично уравнение на топлинна дифузия, с известни характеристики, използвани като гранични условия. FP се получава като дискретизация на това уравнение на дифузия, като се използва изрична предна схема на Ойлер с единичен размер на стъпката [8].
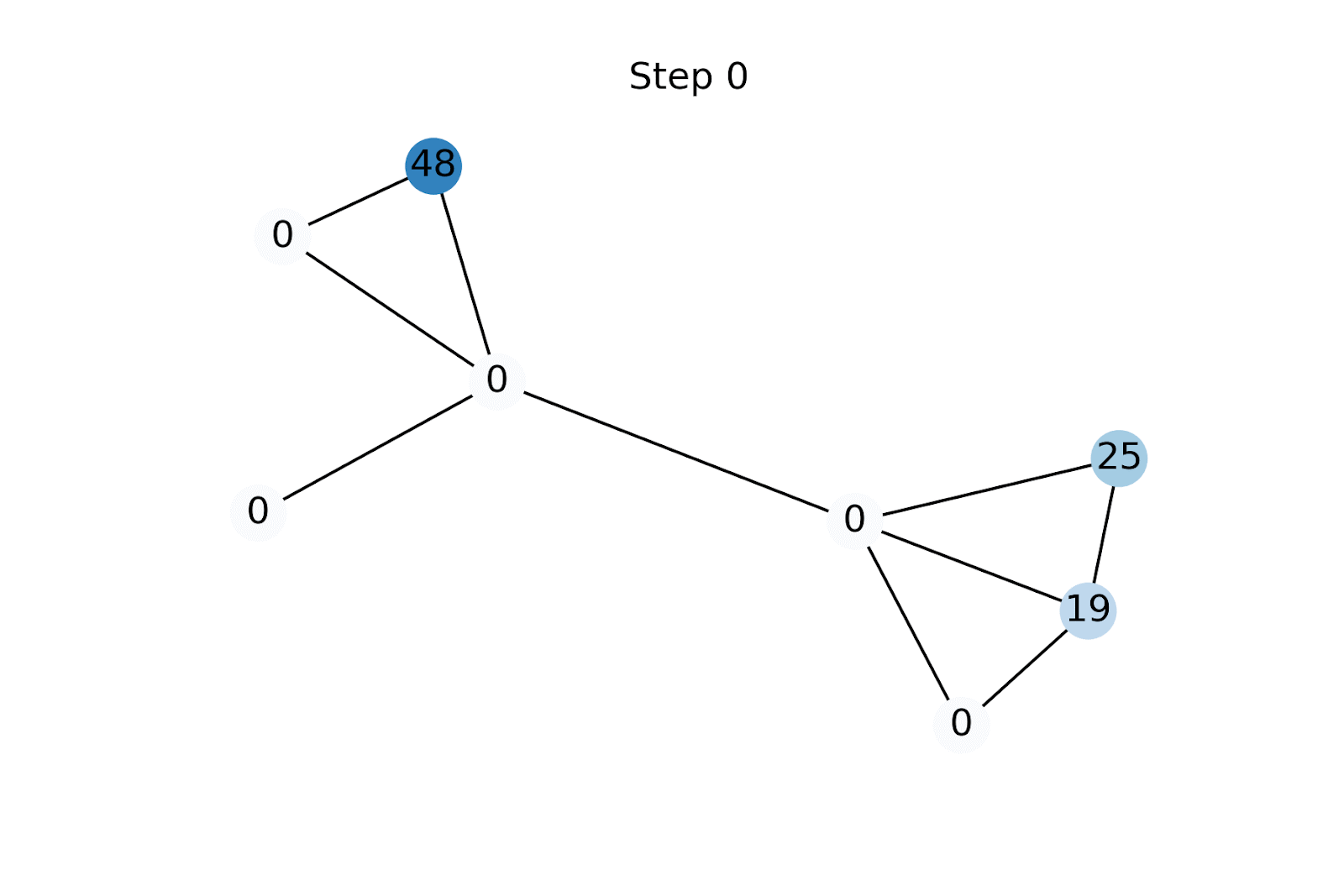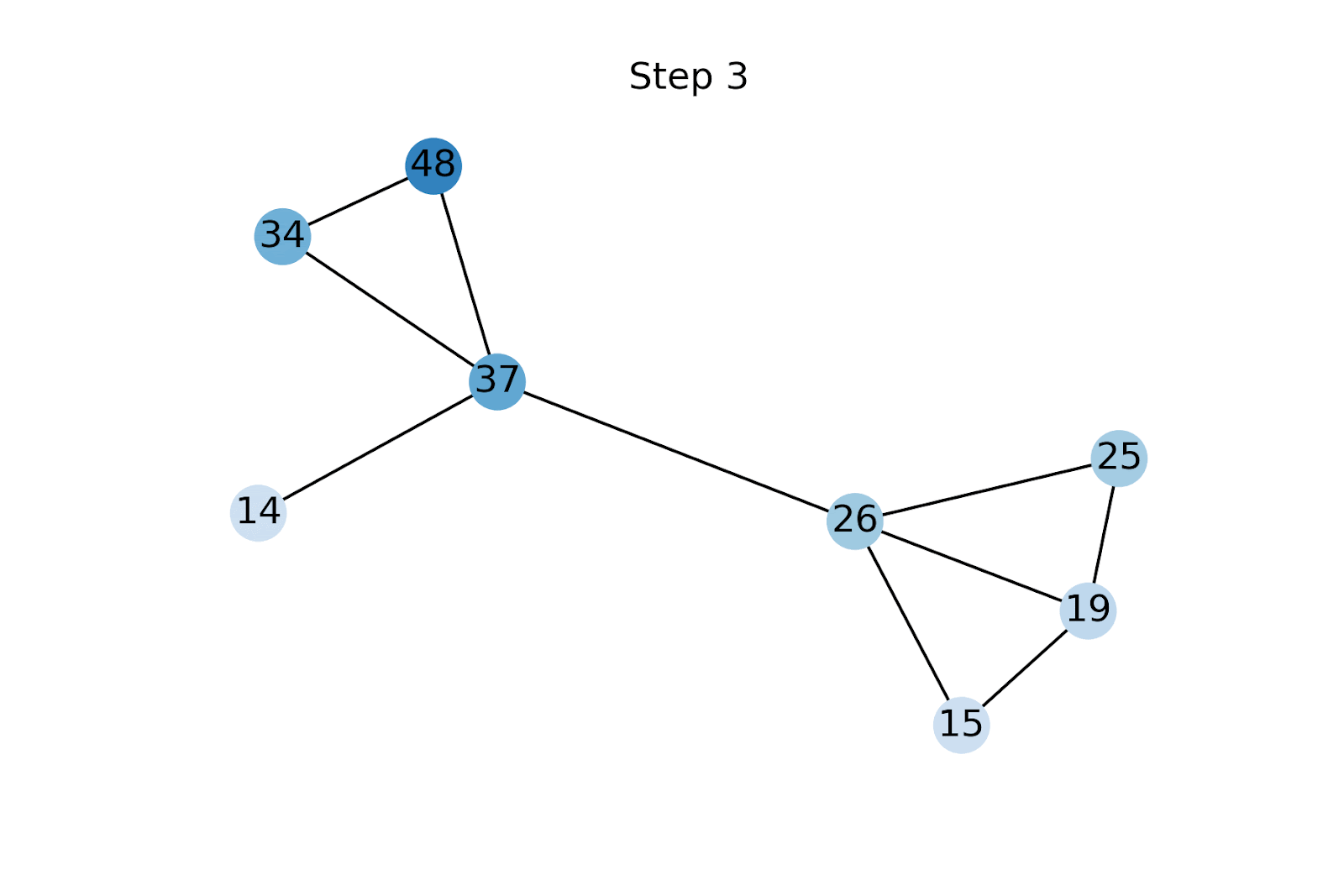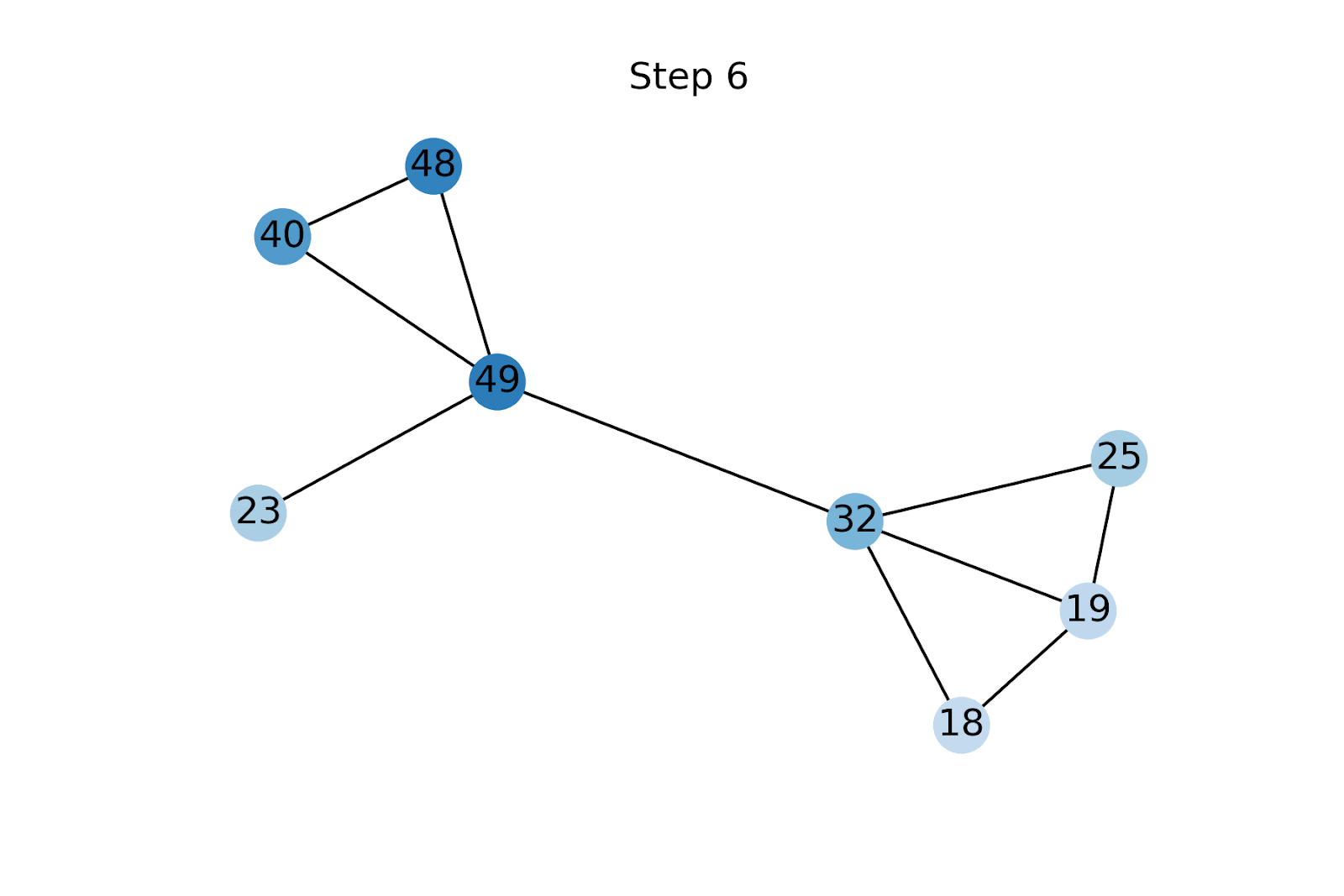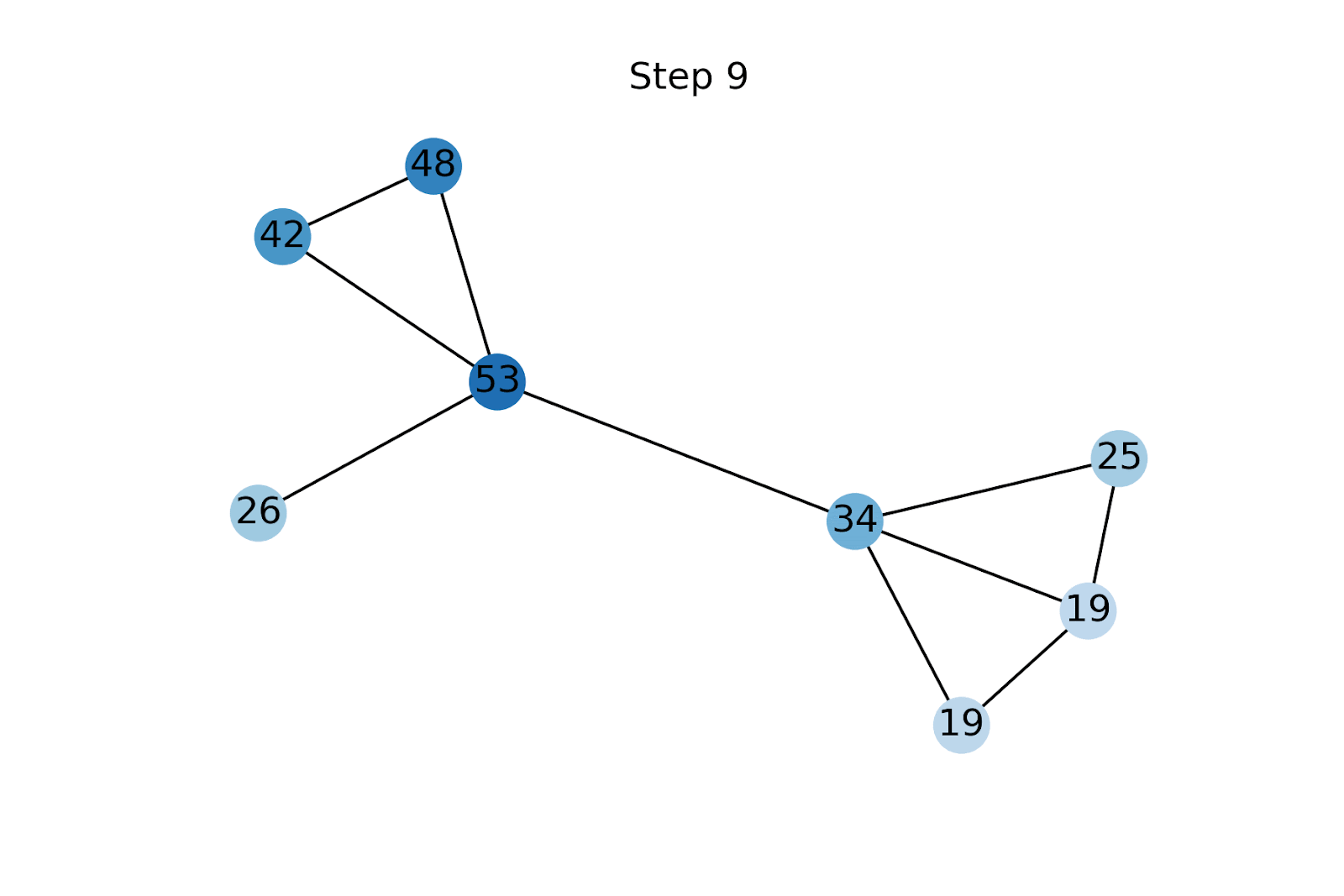
Функционалното размножаване е подобно на разпространението на етикети (LP) [9]. Ключовата разлика обаче е, че LP е функционално агностичен метод и директно предвижда клас за всеки възел чрез разпространение на известните етикети в графиката. От друга страна, FP се използва за първо реконструиране на липсващите характеристики на възел, които след това се подават в GNN надолу по веригата. Това позволява на FP да се възползва от наблюдаваните функции и да надмине LP на всички бенчмаркове, с които експериментирахме. Освен това на практика често се случва наборите от възли с етикети и тези с характеристики да не се припокриват непременно напълно, така че двата подхода не винаги са директно сравними.
Проведохме обширно експериментално валидиране на FP, използвайки седем стандартни бенчмарка за класификация на възли, в които на случаен принцип премахнахме променлива част от характеристиките на възлите (независимо за всеки канал). FP, последван от двуслоен GCN върху реконструираните характеристики, значително надмина простите базови линии, както и най-новите най-съвременни методи [2–3].
FP особено блестеше в режими с високи нива на липсващи характеристики (>90%), където всички други методи са склонни да страдат. Например, дори при липса на 99% от функциите, FP губи само около 4% от относителната точност средно в сравнение със същия модел, когато всички функции са налице.

Друга ключова характеристика на FP е неговата мащабируемост. Докато конкурентните методи не успяват да мащабират отвъд графики с няколко милиона ръбове, FP може да мащабира до милиарди ръбове на графики. Отне ни по-малко от час, за да го стартираме на нашата вътрешна графика в Twitter с около 1 милиард възли и 10 милиарда ръбове, използвайки една машина.

Сред настоящите ограничения на FP е, че не работи добре на хетерофилни графики, т.е. графики, където съседите са склонни да имат различни характеристики. Това не е изненадващо, тъй като FP се извлича от предположение за хомофилия (по силата на минимизирането на енергията на Дирихле чрез уравнението на дифузията). Освен това, FP приема, че различните канали за характеристики не са корелирани, което рядко се случва в реалния живот. Приспособяването и на двете ограничения е възможно с алтернативни по-сложни дифузионни механизми.

Обучението върху графики с липсващи функции на възли е почти неизследвана изследователска област, въпреки повсеместното му разпространение в приложенията от реалния свят. Ние вярваме, че нашият модел за разпространение на функции е важна стъпка към напредъка на способността за учене на графики с липсващи характеристики на възли. Освен това повдига дълбоки въпроси относно теоретичната способност за учене в тази среда като функция на предположения за сигнала и структурата на графиката. Опростеността и мащабируемостта на FP, заедно с удивително добри резултати в сравнение с по-сложни методи, дори в екстремни режими на липсващи функции, го правят добър кандидат за използване в широкомащабни индустриални приложения.
[1] T. Kipf и M. Welling, Полуконтролирана класификация с графични конволюционни мрежи (2017), ICLR.
[2] H. Taguchi et al., Графични конволюционни мрежи за графи, съдържащи липсващи характеристики (2020), Компютърни системи от бъдещо поколение.
[3] X. Chen и др., „Изучаване на графики с липсващи атрибути“ (2020), arXiv:2011.01623
[4] Е. Роси и др., Относно неразумната ефективност на разпространението на функции при обучение на графики с липсващи характеристики на възел (2021), arXiv:2111.12128
[5] Показваме, че алгоритъмът се свежда до едно и също решение, независимо от инициализацията на неизвестните стойности. Различната инициализация обаче може да доведе до различен брой итерации, необходими за сближаване. В нашите експерименти ние инициализираме неизвестните стойности на нула.
[6] Установихме, че ~40 итерации са достатъчни за конвергенция на всички набори от данни, с които експериментирахме.
[7] Градиентният поток може да се разглежда като непрекъсната аналогия на градиентното спускане в вариационни проблеми. Произтича от условията за оптималност (известни в вариационното смятане като уравнения на Ойлер-Лагранж) на функционал.
[8] Б. Чембърлейн и др., GRAND: Графична невронна дифузия (2021), ICML. Вижте също „придружаващата публикация в блога“.
[9] X. Zhu и Z. Ghahramani, Учене от маркирани и немаркирани данни с разпространение на етикети (2002), Технически доклад.
Благодарни сме на Henry Kenlay и Davide Eynard за корекцията на тази публикация. За допълнителни статии относно задълбочено обучение върху графики вижте другите публикации на Майкъл в Towards Data Science, абонирайте се за неговите публикации и YouTube канал, вземете Средно членство или следвайте Майкъл и Емануеле в Twitter.