
Логистичната регресия е пример за контролирано обучение. В тази статия ще ви отведем на едно вълнуващо пътешествие в царството на логистичната регресия, където ще научите какво представлява тя, ще разгледате нейните основни типове, ще я сравните с линейната регресия, ще балансирате нейните предимства и недостатъци и ще научите за нейните приложения от реалния свят. Подгответе се да отключите силата на логистичната регресия и пътувайте по едно вълнуващо пътешествие с прозрения, управлявани от данни!“
Какво е логистична регресия?
Когато има непрекъсната променлива за прогнозиране, но трябва да бъде класифицирана в двоична форма, използваме логистична регресия. Това контролирано обучение се използва за изчисляване или прогнозиране на двоична вероятност (да или не настъпили събития).

Например: треска или не, рак или не, печалба или загуба, успешно или неуспешно. Целта на логистичната регресия е да се намери връзката между независимите променливи и двоично зависимите променливи, приемащи стойност 0 или 1.
Графичното представяне на логистичната регресия:

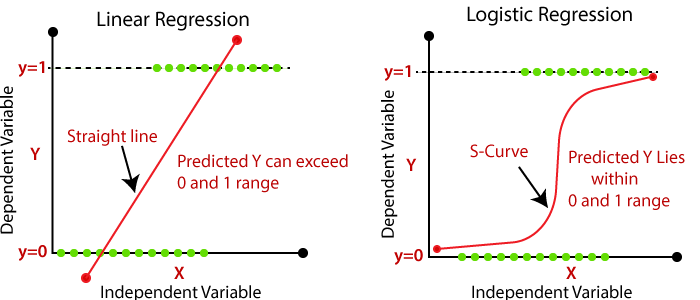
Линейна регресия срещу логистична регресия
Както линейната, така и логистичната регресия са статистически модели, но имат някои ключови характеристики.
Първо, нека видим какво е линейна регресия и логистична регресия.
Линейна регресия
Линейната регресия се използва за моделиране на връзка между непрекъснати зависими и независими променливи. Резултатът от тази променлива може да бъде всяка стойност. По същество целта на този модел е да се определи най-подходящото линейно уравнение, което представлява връзката между независимата променлива и зависимата променлива.
Математическият израз за линейна регресия е, че:

където:
- y е зависимата променлива, това е стойността, която трябва да се предвиди“
- x е независимата променлива, която е променливата, която се използва за прогнозиране
- b0 е пресечната точка, а b1 е наклонът
- e е остатъчната грешка, което означава разликата между напасната линия и точката. Тази грешка може да бъде положителна или отрицателна.
Графично представяне:

Логистична регресия
В логистичната регресия вместо да напасваме линия, ние използваме крива, наречена сигмоидна крива. На фигура: 1.2 S-образната крива е сигмоидната крива, известна също като сигмоидна функция или логистична функция, която съпоставя всяко реално число с вероятността между 0 и 1.
Функцията на максимална вероятност за оценка на параметри е най-често срещан метод, използван в логистичната регресия. Намирането на стойностите на коефициента, които увеличават максимално вероятността от наблюдаваните данни, е основната цел на този метод за оценка. По време на процеса на обучение логистичният регресионен модел научава коефициентите за независимите променливи, които увеличават максимално вероятността за наблюдаваните двоични резултати в данните за обучение. След като моделът е обучен с помощта на MLE, прагът се прилага за прогнозиране на вероятностите за получаване на двоичната класификация. Тъй като праговата стойност е зададена по подразбиране на 0,5, всяка вероятностна стойност над 0,5 се счита за положителна, а всяка стойност под 0,5 се счита за отрицателна. Праговата стойност обаче може да се коригира в зависимост от конкретен проблем.
Математическото представяне на логистичната регресия е, че:

Фигура 1.4 изобразява как изведехме логистичната регресия от линейното уравнение. Това е чрез заместване на стойността на сигмоидната функция по отношение на у в уравнението на правата.
Ключовите разлики между логистичната регресия и линейните регресии са:
- Линейната регресия се използва за справяне с регресионни проблеми, които включват прогнозиране на непрекъснатата числовастойност като изход, докато логистичната регресия се използва за справяне с класификационни проблеми, които включват прогнозиране на дискретни категории или класове като изход.
- Линейна, изисква да има връзка между зависима и независима променлива и тази връзка може да бъде представена в права линия, но логистиката не изисква този вид връзка. Вместо това той използва вероятността от данни чрез логистична функция (сигмоидна функция).
- Въз основа на предположението, че всички други променливи са постоянни, коефициентите на линейна регресия показват как промяна с една единица в предикторните променливи ще повлияе на резултатите. От друга страна, коефициентите в логистичната регресия, като се предполага, че всички други променливи остават постоянни, показват промяната в логаритмичните шансове на двоичния резултат, свързана с промяна с една единица в променливата на предиктора. (Log-odds е естественият логаритъм от шансовете, който е съотношението на вероятността двоичният резултат да се случи към вероятността той да не се случи.
- Например: В случай на прогнозиране дали даден студент ще издържи изпита или не, в линейната регресия (фигура 1.2), можем да напаснем линейна линия по отношение на независимите променливи, като например часа, който студентът е учил. Въпреки това, линейната регресия може да не е идеална за този случай, тъй като не може да предскаже точно дали студентът е издържал или не е преминал изпита. Тъй като, когато в този случай се приложи линейно уравнение, изходът ще бъде успешно/неуспешно =,където x е изучаваният час, е коефициентът. Изходната стойност няма да варира между 0 и 1. От друга страна, в случай на логистична регресия, фиг. 1.1, можем да моделираме вероятността студентът да издържи изпита или не, като използваме сигмоидната функция. За да се увеличи максимално възможността за откриване на реалната продукция, логистичният регресионен модел ще оцени коефициентите (0 и 1). Използвайки прагово число, очакваната вероятност може след това да се използва за класифициране на ученика като преминал или неуспешен. (напр. 0,5).
Видове логистична регресия
Има основно три вида логистична регресия
· Двоична логистична регресия:
Логистичната регресия е връзката между независимите и зависимите променливи. Тук зависимата променлива е двоична, което означава, че те могат да приемат само две възможни стойности, които са 0 или 1. Например дали човек купува продукт или не, дали някой преминава или се проваля за изпита, ако е дъждовен ден или не.
·Мултиномиална логистична регресия:
Мултиномиалната логистична регресия е статистически модел, използван за моделиране на връзката между зависими променливи и две или повече независими променливи. Тук зависимите променливи са категорични и могат да бъдат две или повече и които не са подредени. Например медицински заболявания като (болест A, болест B, болест C), животни (кучета, котки, овце, мишки).
· Ординална логистична регресия:
Това е статистически модел, използван за моделиране на връзката между последователни зависими променливи и две или повече независими променливи. Тук зависимата променлива е ординална, което означава, че е подредена, например оценката на учениците (отлични, добри, средни, под средните, лоши) или здравословно състояние (критично, сериозно, леко, здраво).
Плюсове и минуси на логистичната регресия
Предимства:
· Може лесно да се приложи, когато данните могат да бъдат линейно разделени.
· Има голяма способност за разширяване до множество класове като многочленна и ординална логистична регресия.
· Може бързо да класифицира записи, които са неизвестни.
· Работи добре за много прости набори от данни и има добра точност, когато наборът от данни може да бъде разделен линейно.
· Тъй като актуализирането на логистична регресия е сравнително лесно, по всяко време можем да добавим нови данни към съществуващия набор от данни. Това помага да се подобри точността и полезността на модела с течение на времето.
· Благодарение на своите ефективни възможности за обработка, той може да обработва огромни масиви от данни. Това го прави ефективен инструмент за изучаване на проблеми с двоична класификация с големи количества данни.
НЕДОСТАТЪЦИ:
· Основният недостатък на логистичната регресия е допускането за линейност между зависимата променлива и независимата променлива. Следователно тази регресия може да не е най-добрият модел за използване за проблеми, при които връзката между променливите е сложна или логистичната регресия изисква средна или никаква мултиколинеарност между независими променливи.
· Има голяма вероятност моделът да бъдепрекомерен. За да бъдем точни, при логистичната регресия, когато данните съдържат множество независими променливи, моделът може да се опита да напасне шума в данните, което води до ниска производителност на обобщение. По същия начин, когато размерът на извадката е твърде малък, може да няма достатъчно данни за оценка и моделът има шанс да бъде пренастроен.
· Сложните връзки са трудни за получаване с помощта на логистична регресия.
· Логистичната регресия изисква голям размер на извадката, така че да може да произведе точни оценки на коефициента. Напротив, моделът не може да оцени точно, когато размерът на извадката от данни е минимален.
· Логистичната регресия е ограничена до двоична класификация и е предназначена основно за решаване на тези видове проблеми с класификацията, т.е. когато стойностите на зависимата променлива могат да бъдат 0 или 1, или „да“ или "не". Възможно е обаче също така да се използват проблеми, които имат повече от два резултата, като мултиномиална класификация.
· Логистичната регресия е чувствителна към очертания. Логистичната регресия може да бъде чувствителна към отклонения в данните, които могат да повлияят на оценките на коефициентите и цялостната ефективност на модела.
Приложения на логистичната регресия.

Има няколко реални приложения за логистична регресия, особено когато се опитвате да прогнозирате двоични резултати.
1. Медицинско поле: логистичната регресия може да се използва за прогнозиране на заболяване на пациенти въз основа на тяхната медицинска история и друг рисков фактор. Освен това може да се използва и за идентифициране на рисков фактор, изследване на резултатите от терапията и др.
2. Кредитен рейтинг: В банки и други финансови институции моделът на кредитен рейтинг, базиран на логистична регресия, най-често се използва за валидиране на оценката на кредитния риск. Тук способността на кредитополучателя да изплати заема е зависимата променлива, докато различни други характеристики, като например доходите на кредитополучателя и положението на работата, са независимите променливи.
3. Политическо прогнозиране: Логистичната регресия може да се използва за прогнозиране на изборния резултат. Зависимата променлива е дали конкретният кандидат печели или не, докато независимата променлива е поведението на избирателя, политическите възгледи. За да прогнозират резултатите от изборите, социологическите компании и медиите често използват модели за политическо прогнозиране, базирани на логистична регресия.
4. Откриване на измама: Основната цел на това е да се установи къде е възникнало измамното поведение въз основа на входните функции
5. Игри: Сегментирането на играча и отливът на играча могат да бъдат предвидени чрез използване на логистична регресия чрез анализиране на поведението на играчите, като честота на играната игра, тип играна игра и покупки в играта.
Заключение
В заключение, контролираното обучение е основен предмет в машинното обучение, който обхваща както моделите за класификация, така и регресията. Тук обсъдих логистичната регресия, която принадлежи на алгоритъма за класификация. Тази регресия се използва, когато зависимата променлива е категорична. Въпреки че има различни ограничения като чувствителност към очертания и висока вероятност от пренастройване, той се използва широко при проблеми от реалния свят, като например в областта на медицината, кредитния рейтинг, политическите прогнози и дикцията за измами.
За да разберете практическата страна на логистичната регресия, щракнете върху връзката тук!
Надявам се, че ви е харесало!