Ключови изводи
- Сравнение на точността на превода между Google Translate, DeepL, GPT-3.5, GPT-4 и MarianMT на 24 езикови двойки.
- Анализ на разходите за използване за различни модели.
- Кодът за машинен преводач, използващ GPT-3.5/GPT-4 API.
Моделите GPT-3.5/GPT-4 са способни да решават огромното мнозинство от NLP задачи, включително машинен превод.
В един момент започнах да се чудя как тяхната производителност на превод се сравнява със специализирани инструменти за превод като Google Translate и DeepL.
В тази статия ще сравня пет решения
- MarianMT: семейство модели за превод за различни езикови двойки, прецизирани от изследователската група Helsinki-NLP. Тези модели са достъпни безплатно на HuggingFace и можете да ги стартирате на собствения си компютър. Има "големи" (~ 500 MB) и "малки" (~ 300 MB) модели; за повечето езикови двойки съществува само малката версия. Ще използвам големите версии, когато е възможно.
- API за превод на Google Cloud Platform: той използва същия модел, който захранва Google Translate. Цената на API е $20 за 1 милион знака.
- DeepL API: DeepL е солиден конкурент на Google Translate. Той също така предлага търговски API на подобна цена.
- GPT-3.5 API: Ще използвам техниката за решаване на проблеми seq2seq, която обясних в предишната статия.
- API на GPT-4: Същото като решението на API на GPT-3.5, но базовият езиков модел е GPT-4 вместо GPT-3.5. Това решение ще бъде много по-скъпо от GPT-3.5, но се очаква да работи много по-добре.
Избрах 12 често срещани езика: испански, мандарин китайски, френски, немски, японски, португалски, руски, корейски, холандски, хинди, индонезийски и арабски. За всеки от тях ще тествам превода от този език на английски и от английски на езика.
Изключения са:
- DeepL не поддържа хинди и арабски.
- Моделът MarianMT за английски → корейски изглежда е повреден, тъй като извежда глупости дори в демонстрацията на Hugging Face, така че няма да го използвам.

Ще използвам резултата BLEU за измерване на точността на превода.
Събиране на данни
Създадох персонализиран набор от данни въз основа на изречения на Tatoeba. За всяка езикова двойка тестовият набор включва или 50, или 100 от най-дългите паралелни изречения на Tatoeba, които са изпратени след септември 2021 г.
Избрах само новите изречения, за да се боря със замърсяването на данните, тъй като те не можаха да се появят в данните за обучение за GPT модели. Това гарантира, че моите тестове не надценяват производителността на GPT-3.5 и GPT-4.
Да, може да има някои ефекти на замърсяване на данните, които се случват с Google Translate и DeepL, защото не знаем нищо за техните данни за обучение. Това потенциално поставя други модели в малко неизгодно положение.
Резултатите от MarianMT обаче не трябва да бъдат склонни към замърсяване на данните, тъй като моделите са обучени върху набора от данни OPUS и са тествани на Tatoeba дори от самите Helsinki-NLP.
Реших да използвам възможно най-дългите изречения, за да направя задачата за превод по-предизвикателна. Когато става въпрос за кратки изречения, различните резултати от моделите от най-високо ниво често са просто различни граматически правилни формулировки с абсолютно същото значение.
Качество на превода
Оптимизирах подканата за GPT-3.5/GPT-4 модели по същия начин, както направих в предишната статия.
Най-доброто системно съобщение се оказва:
Моля, преведете потребителското съобщение от {src} на {tgt}. Направете превода да звучи възможно най-естествено.
Второто изречение е наистина важно тук, тъй като значително повишава резултата BLEU.
В тази задача използването на няколко примера всъщност влошава качеството в повечето случаи. Възможно е леко да се подобри качеството чрез грубо форсиране чрез различни набори от примери, но се усеща като пренастройване конкретно на стила на изречението Tatoeba. Поради тази причина изобщо не използвам кратки примери.
За всяка езикова двойка визуализирах разпределението на резултата на BLEU за различни модели, използвайки диаграми на кутии на matplotlib.
Ето папката repo, съдържаща .json отчетите за всички езикови двойки и всички модели: https://github.com/einhornus/prompt_gpt/tree/main/data/translation/reports. Всеки отчет съдържа списък с изречения (оригиналното изречение, очакваният превод, моделът на превода, СИНЯТА оценка), сортирани по BLEU оценката.






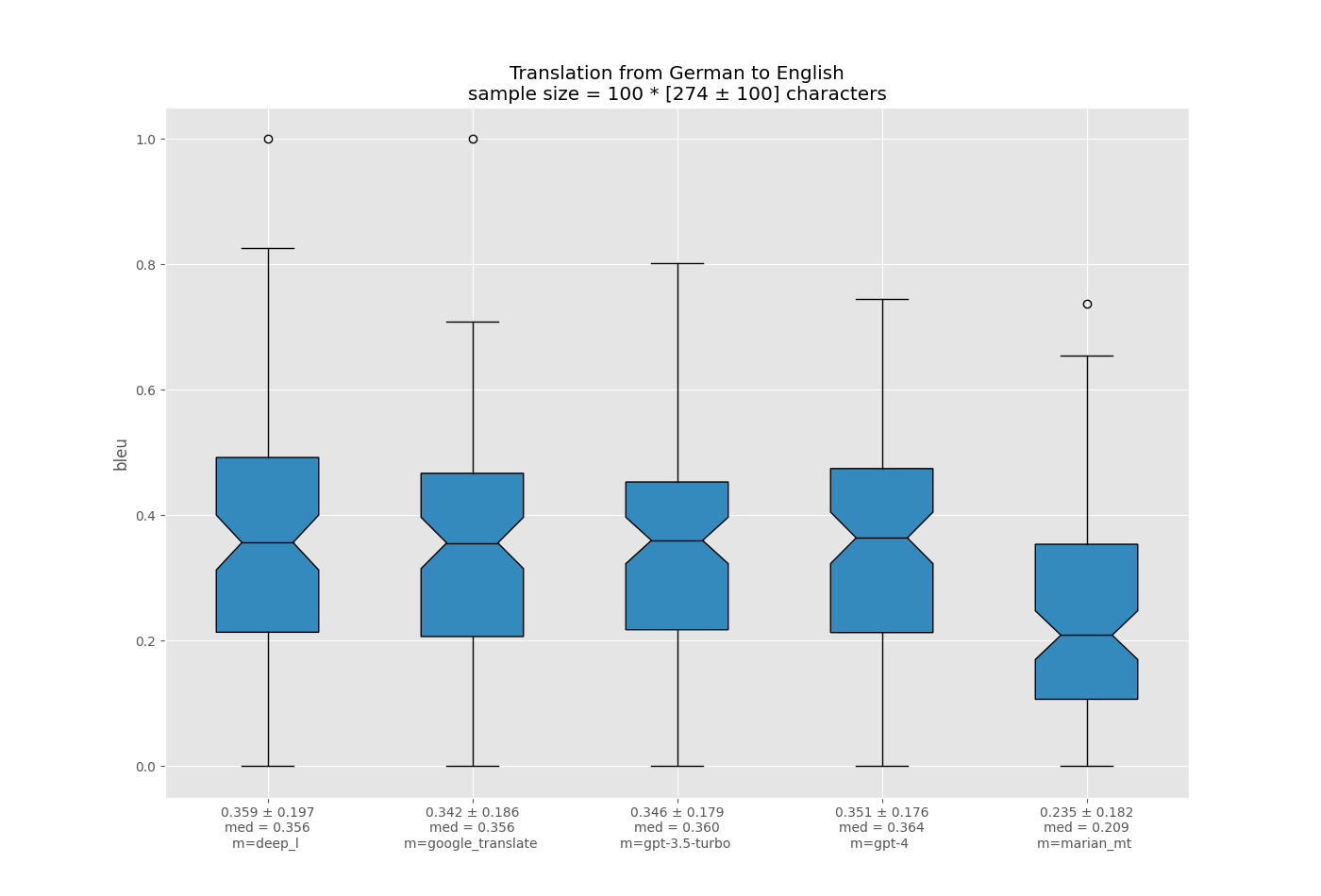

















Като разгледах по-отблизо отчетите за изреченията, открих някои допълнителни прозрения
- MarianMT често създава неграматични изречения на езици, различни от английски. Например, в английски → руски примери, BLEU резултатът на MarianMT е близък до този на GPT-3.5, но MarianMT допуска много граматически грешки, докато GPT-3.5 не.
- В подгрупата английски → руски ми се струва, че GPT-3.5 има тенденция да прави много „малки“ грешки, което прави резултата да звучи „леко неестествено“ като цяло, докато Google Translate прави няколко големи грешки. Имам теория, че превъзходният резултат на Google Translate идва от факта, че резултатът BLEU е много наказателен спрямо първото поведение, което прави GPT-3.5 да изглежда недостатъчно по отношение на BLEU.
- Намерих някои примери за Google Translate, генериращи очаквания резултат дословно в дълги изречения. Това силно предполага замърсяване на данните.
- Изглежда, че GPT-3.5 променя действителния смисъл на изречението далеч по-рядко от Google Translate, което е донякъде парадоксално предвид по-ниския му BLEU резултат.
Анализ на разходите
API за превод на Google Cloud Platform струва $20 за 1 милион знака.
DeepL API струва $4,5 фиксирана сума на месец + $18 за 1 милион знака.
Ценообразуването на GPT API е по-сложно, тъй като плащате за използваните токени. Лексемите са думи и части от думи; за английски средно около 4 знака образуват токен. Вие също така плащате както за токени за подкана (което включва вход), така и за токени за завършване (изход): $0,002/1k токени от всякакъв вид с GPT-3.5 API и $0,03/1k за токени за подкана плюс $0,06/1k за токени за завършване с GPT- 4 API.
Изчислих средното съотношение знак на токен за текстове на различни езици. Обикновено, ако даден език не използва латиница, това съотношение ще бъде по-ниско, така че API за този език ще струва повече. Има обаче две изключения: китайски и японски. Въпреки че имат много ниско съотношение знак на токен, китайските и японските текстове заемат значително по-малко знаци от еквивалентните английски текстове.

Таблицата по-долу взема предвид всичко това и показва приблизителната цена в центове за превод на съобщение от 500 знака.

В повечето случаи GPT-3.5 ще бъде 5–15 пъти по-евтин от Google Translate, докато GPT-4 ще бъде 1.2–4 пъти по-скъп от Google Translate. Точното съотношение на разходите зависи от езиковата двойка.
Код на транслатора GPT-3.5/GPT-4
Ето кода, който използва API за превод на изречение
import openai
import os
def translate(sentence, source_lang, target_lang, model = "gpt_3.5-turbo"):#source_lang, target_lang are names of the languages, like "French"
openai.api_key = os.environ.get("OPENAI_API_KEY") #or supply your API key in a different way
completion = openai.ChatCompletion.create(
model=model,
messages=[
{
"role": "system",
"content": f"Please translate the user message from {source_lang} to {target_lang}. Make the translation sound as natural as possible."
},
{
"role": "user",
"content": sentence
}
],
temperature=0
)
return completion["choices"][0]["message"]["content"]
Изводи
- Относителната производителност на GPT-3.5 и GPT-4 до голяма степен зависи от езиковата двойка
- DeepL постоянно побеждава Google Translate на повечето езикови двойки.
- Google Translate обикновено превъзхожда GPT-3.5 по отношение на резултатите от BLEU; има обаче някои езикови двойки, при които това не е така. Въз основа на прозрения от качествен анализ бих поставил под въпрос твърдението, че GPT-3.5 е по-лош от Google Translate, тъй като резултатите от Google Translate са повлияни от замърсяване на данни. Има и силни аргументи в подкрепа на теорията, че превъзходният BLEU резултат на Google Translate произтича от начина, по който се изчислява този показател.
- GPT-4 е значителна стъпка напред от GPT-3.5, когато става въпрос за задачи за превод. GPT-4 превъзхожда Google Translate дори по отношение на BLEU на около половината езикови двойки и дори надминава DeepL на някои от тях. И така, отговаряйки на въпроса от заглавието: да, GPT-4 като цяло превъзхожда Google Translate.
- GPT-3.5 е много достъпен в сравнение с Google Translate и DeepL. GPT-4 обаче е значително по-скъп.
- Резултатите на MarianMT не са много впечатляващи в сравнение с други модели. Въпреки това е отворен и безплатен и може да създаде достатъчно добри преводи за „прости“ езикови двойки като испански → английски. Когато става въпрос за трудни езици (като японски, китайски, корейски или арабски), не очаквайте от MarianMT да се представи добре.
- Моделите на Google Translate и GPT основно поддържат всички езици, които някога бихте искали да имате. DeepL поддържа само 29 езика и много популярни езици като хинди, арабски, урду, бенгалски, маратхи, виетнамски, тагалог и хърватски не са включени в този списък.
- GPT API е по-бавен в сравнение с Google Translate и DeepL.
- GPT моделите са по-гъвкави; те могат да бъдат допълнително персонализирани за повишаване на качеството. Например, можете да генерирате няколко различни превода, като се възползвате от температурния параметър или използвате различни подкани, и след това изберете превода, който е най-близо до въведения текст семантично (използвайки техники като многоезичен BERT).