
Ако сте тук, знаете, че PyTorch е една от най-популярните библиотеки сред практикуващите дълбоко обучение. Той е високоефективен и неговата гъвкавост улеснява писането на персонализиран код, когато на алгоритмите липсват определени функционалности, необходими във вашите проекти.
Работата с кодовата база на PyTorch обаче може да бъде смущаваща, особено ако сте свикнали да работите само с абстракции на високо ниво. В тази публикация в блога ще се потопим във вътрешната архитектура на PyTorch. По-конкретно, ще проучим два критични компонента, които улесняват ефективните изчисления:Tensor Wrappers и Kernels.
Ние ще покрием:
- Tensor Wrapper (напр. групови тензори)
- Анатомия на операторско обаждане
- Писане на ядра
- За по-ефективен работен процес на разработка
- Допълнителни ресурси
Да започваме 🚀
Tensor Wrapper (напр. групови тензори)
PyTorch Tensor има добре проектирани метаданни, които отделят оформлението на логическата памет от физическата памет и предоставят примитиви за динамично изпращане на оператори от интерфейса на Python към високопроизводителния бекенд на C++. Всеки тензор се състои от device, layout и dtype метаданни.
deviceпозволява изпращане на операции на устройство (изпълнени в ядра) за по-добра ефективност.layoutпозволява споделяне на едно и също разпределение на паметта на хардуерно ниво за множество изгледи, отделяйки оформлението на логическия тензор от оформлението на физическата памет. Когато се изисква достъп до действителната физическа памет,TensorAccessorще използва оформление (напр. крачка) за достъп до тензорни елементи. Можете да научите повече заTensorAccessorот този блог или този страхотен подкаст с вътрешни елементи на PyTorch.dtypeпозволява изпращане на операции за dtype (изпълнение в kernesl) за по-добра ефективност чрез макросаAT_DISPATCH_ALL_TYPESвatenядра.

Анатомия на операторско обаждане
При разработването на персонализиран оператор с PyTorch са включени множество стъпки, преди да се извърши изчисление. Този процес включва разбор на аргументи на Python, превключване на тип променлива, превключване на тип данни и в крайна сметка изпращане на ядрото.
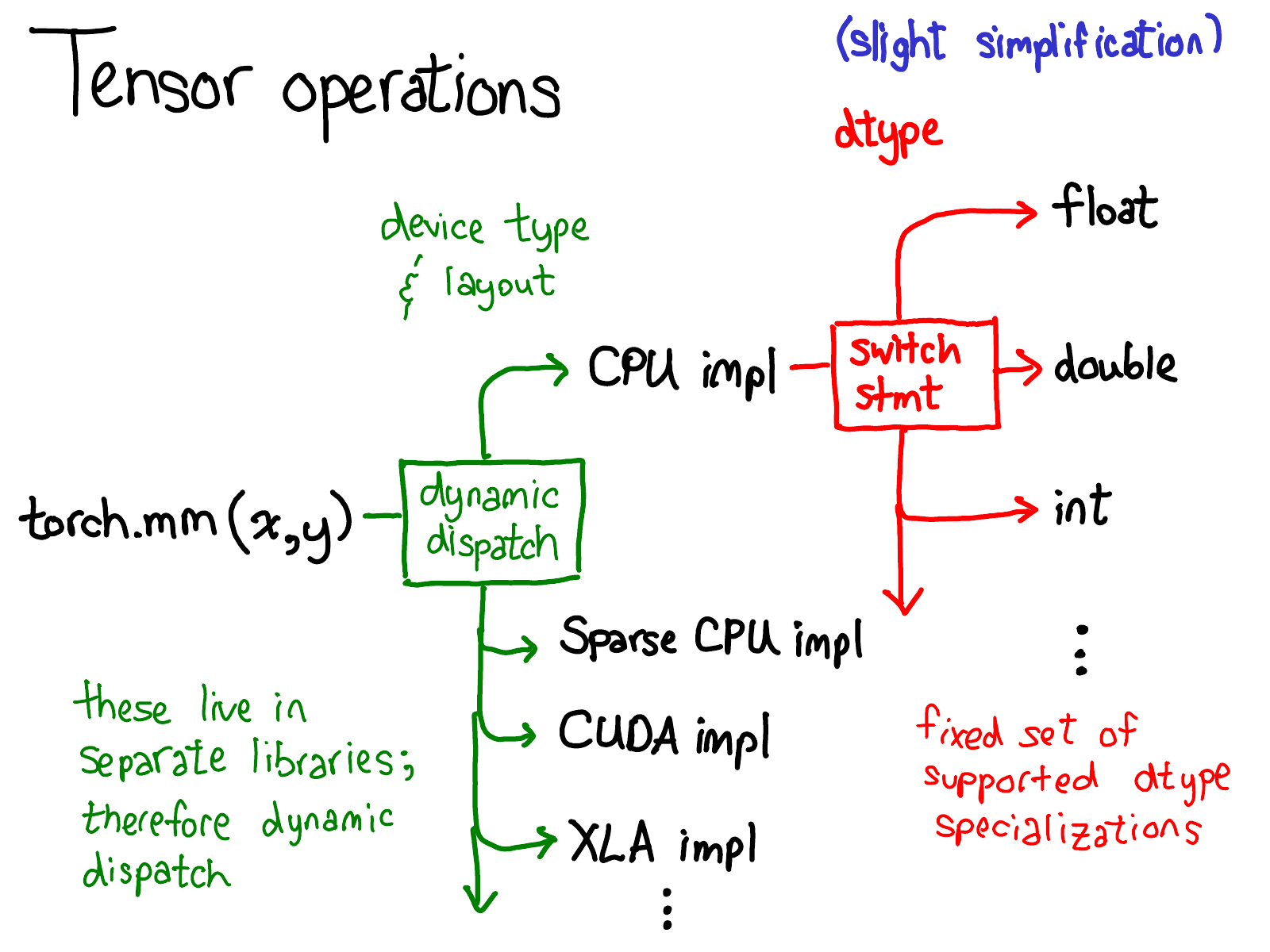
📧 Забележка: Кодът за предаване на изпращането се генерира автоматично от aten/src/ATen/native/native_functions.yaml
Стъпка 1: Разбор на аргументи на Python
- Все още сте в страната на питоните 🥳
- Целта на тази стъпка е да предаде аргумент на Python към обвързвания на C++чрез
torch/csrc - Например:
torch.add→THPVariable_add(приtorch._C.VariableFunctions, автоматично генерирано)
Стъпка 2: Превключване на променлив тип
- Вече сте в сериозна
atenC++ земя 🥸 - Целта на тази стъпка е да пренасочи операции към функции, съответстващи на
deviceна тензор - Например:
THPVariable_add→VariableDefault::add(наaten/src/Aten/TypeDefault.app, автоматично генерирано)
Стъпка 3: Превключване на типа данни
- Вече сте в страната на ядрото 🚀. Тук нещата са специфични за устройството!
- Целта на тази стъпка е да пренасочи операциите към функции, съответстващи на
dtypeна тензор - С тази стъпка стигнахме до правилното ядро, то може да бъде в по-добрата част на града (
nativeв C++) или в по-лошата страна на града (THв C).
— `VariableDefault::add` → `at::native::add` (в `aten/src/Aten/native/BinaryOps.cpp`)
Струва си да подчертаем отново, че целият код, докато стигнем до ядрото, се генерира автоматично. Това е малко криволичещо и въртящо се, така че след като имате някаква основна ориентация за това, което се случва, се препоръчва просто да преминете направо към ядрата.

Писане на ядра
При писането на ядрата са включени няколко стъпки. Ето кратък преглед:

- Започнете с проверка за грешки (напр. уверете се, че входните тензори са с правилните размери).
- След това обикновено трябва да разпределим резултатния тензор, в който ще запишем изхода, използвайки
result.resize_(self.sizes());_вresize_означава модификация на място.
3. [Тази стъпка не се изисква от някои устройства] В този момент трябва да направите второто, dtype изпращане, за да преминете към ядро, което е специализирано за dtype, върху което работи. Ще използвате макроса AT_DISPATCH_ALL_TYPES, както говорихме в „Анатомия на операторско повикване“
4. Повечето производителни ядра се нуждаят от някакъв вид паралелизиране. Изпълнението е специфично за устройството.
5. И накрая, трябва да получите достъп до данните и да направите изчислението, което искате да направите!
- Ако просто искате да получите стойност на определено място, трябва да използвате
TensorAccessor. - Ако пишете някакъв вид оператор с много редовен достъп до елементи, използвайте
TensorIterator. Можете да научите повече заTensorIteratorтук. - За истинска скорост на процесора използвайте помощници като
binary_kernel_vec.
За по-ефективен работен процес на разработка
Когато пишете код, няма нищо по-разочароващо от това да промените заглавния файл и да изчакате няколко часа, докато се появят необходимите компилации. Ето няколко съвета за максимизиране на ефективността и скоростта на разработката на вашия PyTorch код:
- Не редактирайте заглавка: Ако редактирате заглавка, особено такава, която е включена от много изходни файлове (и особено ако е включена от CUDA файлове), очаквайте много дълго възстановяване. Опитайте се да се придържате към редактирането на cpp файлове и редактирайте пестеливо заглавките!
- Не тествайте чрез CI: CI е много чудесен, но очаквайте да изчакате час или два, преди да получите обратен сигнал. Ако работите върху промяна, която ще изисква много експерименти, отделете време за създаване на местна среда за разработка.
- Направете настройка на кеша: Ако работите в областта на C++, настройването на CCache може да ви спести много време за изграждане. Ръководството за ПРИНОС обяснява как да настроите ccache.
Заключение
В заключение, вътрешната архитектура на PyTorch е сложна, но много ефективна. Разбирането на Tensor Wrappers и Kernels ви позволява да оптимизирате ефективността на изчисленията, като същевременно гарантирате, че можете да пишете персонализиран код, който да отговаря на нуждите на вашия проект. Надяваме се, че този преглед на вътрешността на PyTorch ще ви помогне да се потопите по-дълбоко в разработката на PyTorch. PyTorch продължава да се развива и развива, така че не забравяйте да бъдете актуализирани с допълнителни ресурси и ръководства за разработка
Допълнителни ресурси:
- Официална Wiki на PyTorch: как да създадете ядро
- Вътрешни елементи на PyTorch TensorIterator
- Подкаст: TensorIterator
- „Как да разбера изходния код на Pytorch?“
- „Обиколка на вътрешността на PyTorch: Част 1“
- „Обиколка на вътрешността на PyTorch: Част 2“
- PyTorch — обиколка на вътрешната архитектура]
- Подкаст: Подкаст за разработчици на PyTorch
- PyTorch Wiki
- „PyTorch Internals от неговия автор“